

PBNs have been around for well over a decade, which may lead some people to believe that they are an outdated technique, but rest assured that PBNs have changed as they have remained a strong SEO strategy for quite some time.
Since old domains are seen by Google as authoritative, this method is beneficial because of the websites that compose a PBN.
Instead of getting links from fresh, untrustworthy websites that Google’s algorithm doesn’t like, you’re getting authority links from older, more established websites that it does.
1. The Tools You Need To Be A Successful Scraper
Scraping domains is actually rather simple once you get the basics down on how to use the tools properly. There are only 4 tools that are required to be successful in scraping some quality expired domains.
we will go each one briefly in this guide and will go more in-depth when we are actually using them.
1. Scrapebox
This is the bread and butter, without Scrapebox we could not find domains very easily. This can seem a little daunting up front to get it all setup properly but once you get used to it , it is easy
2. Proxies
These are essential as we will be doing most of our searching for websites through Google Search Engine and if you have too many requests from a single IP they will blacklist you for a few hours.
if you have ever spent a lot of time searching for your websites rankings and had to insert a captcha everytime you search then you will understand why we must use proxies to maintain quick and effective scraping.
It will cost you around $20 for 10 Dedicated Proxies which will get through ‘Buy Proxies’ as they extremely reliable and they even make sure they send you proxies that are optimized for Scrapebox & Google.
When you checkout they will ask you what they are for and you just select the Scrapebox option to ensure you get quality ones.
check more dedicated proxy servers
3. SEO Services
We are going to be using Majestic for filtering out large amounts of domains using their metrics of ‘Trust Flow’ and ‘Citation Flow’.
These metrics do not necessarily mean that a domain is of good quality but it’s a very good way of filtering out extremely weak domains in terms of SEO value.
You can also use Majestic to check the anchor text and backlinks of a domain to make sure it hasn’t been used for spam in the past as you don’t want a domain that Google has already penalized.
We can’t always be 100% sure a domain hasn’t been penalized but there are a few very good indicators that a domain might have been.
This is relatively expensive at around $49 a month for the Lite package which you will need but if money is a bit tight you can share this monthly fee between 1 or two other people.
4. The Wayback Machine
This tool is really awesome, once a domain has passed all other spam checks we will be putting it through The Wayback Machine which will check for an archived version of the domains website.
Doing this allows us to check that a domain hasn’t been previously used for a Private Blog Network or picked up and turned into a Chinese spam site.
There is no cost for using this.
That’s all the tools we will be using in this training series, super simple right? Next up we are going to go over downloading Scrapebox and setting it all up.
2. Scrapebox Proxy Setup
We are only going to go over how to use paid proxies as it would be a waste of your time trying to scrape domains with free proxies.
Alright now that you understand that we will have to use paid proxies lets head over to buyproxies and create an account where we will grab 10 dedicated proxies.
Here’s the link to the the dedicated proxies
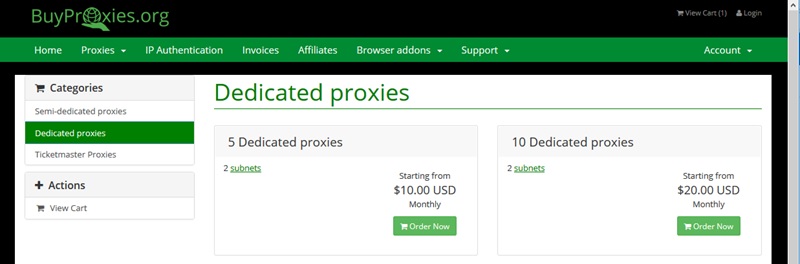
Then you will need to wait a little while, typically only 10-20 minutes but it can be longer. Once you receive an email from them containing your proxies just copy them all. It should look like this
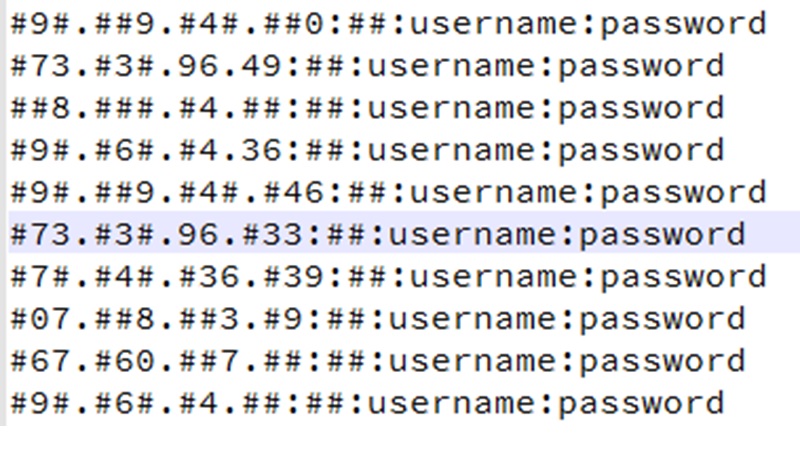
You won’t have the # signs and the ‘username’ and ‘password’ fields will be your unique ones. As long as you mentioned that you are using Scrapebox when purchasing the proxies they will come in the right format to copy & paste.
That format is ip:port:user:pass if yours came in a different format you may need to rearrange them in the above format.
To add the proxies in just click on manage in the proxy section and you will open the ProxyManager.
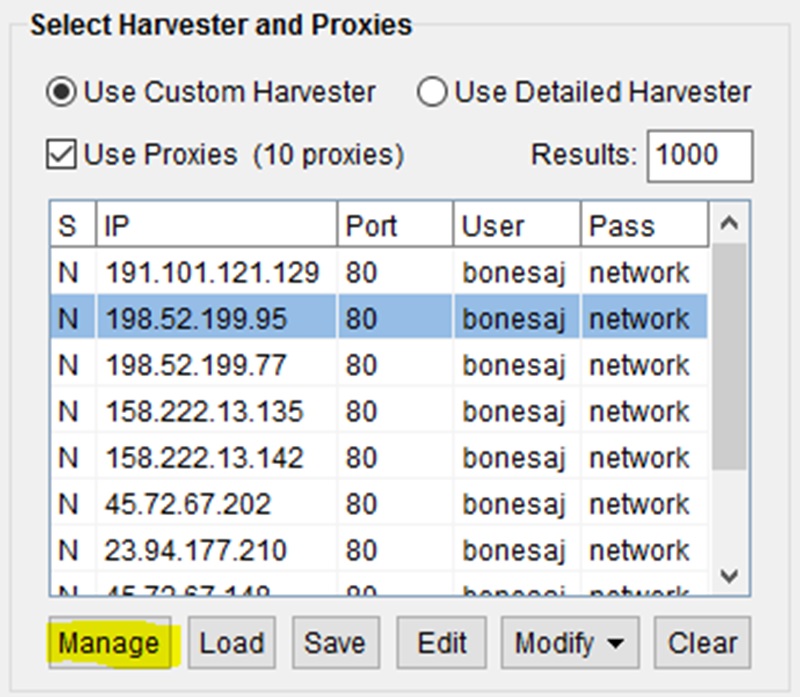
From there we want to go down to load proxies and select ‘Load from Clipboard’.
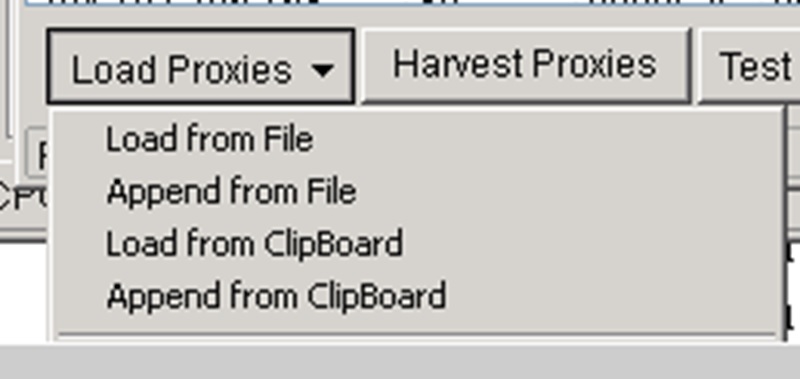
Make sure you copy them from your email first (copy puts them on your clipboard) and it should work fine. Otherwise simply save them to a .txt document and ‘Load From File’ instead.
Once loaded we are going to click on the ‘Test Proxies’ button and click ‘Test All Proxies’.
You should get results back like this:
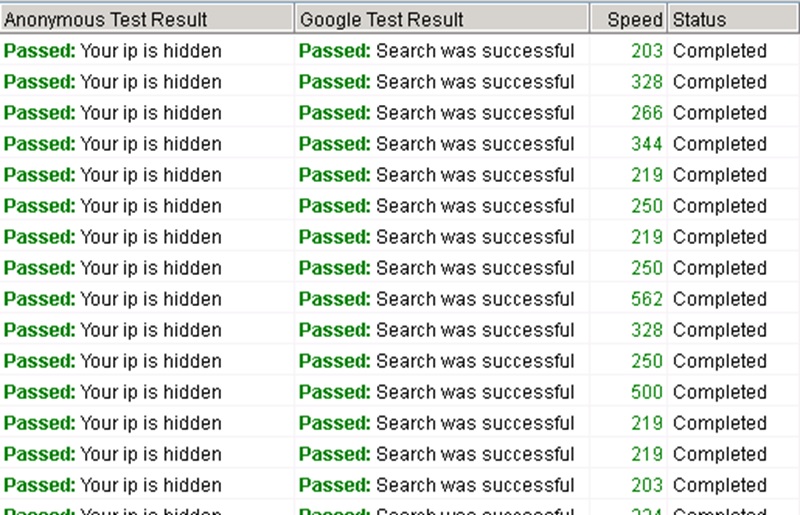
If they are not coming back as passed you may need to send a support ticket to ‘Buy Proxies’ but this has never happened to me before as they test them before sending them to you.
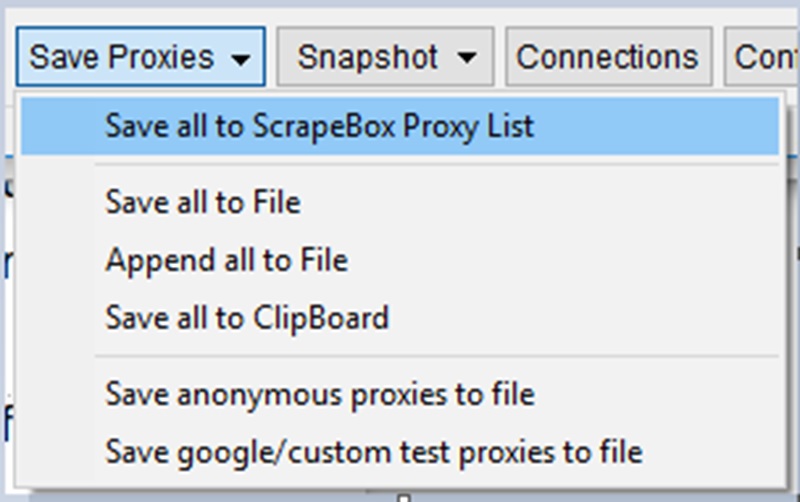
Now click on the ‘Save Proxies’ button and ‘Save all to Scrapebox Proxy List’ and then close this window.
You will now see your proxies in the main window.
3. Creating A Footprint & Getting Keywords
Now we are getting to the interesting part of scraping domains where you get to choose where you want links from.
We are going to scrape a single website such as Wikipedia, BBC or any other large website you like by using a query of “site:domain.com” using the “” are very important so do not leave those out.
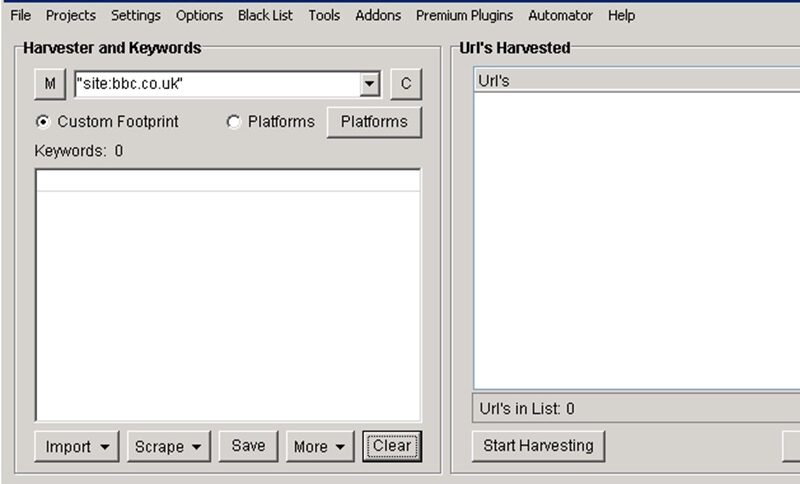
If we were to just hit ‘Start Harvesting’ we would only get a few pages as Google will only return a certain amount of pages back to you for any search results.
To ensure we get a ton more pages from this site we will use the “site:bbc.co.uk” query with a ton of keywords which will give different results based on each keyword.
For example if you wanted to see health related pages of BBC then we would do: “site:bbc.co.uk” health
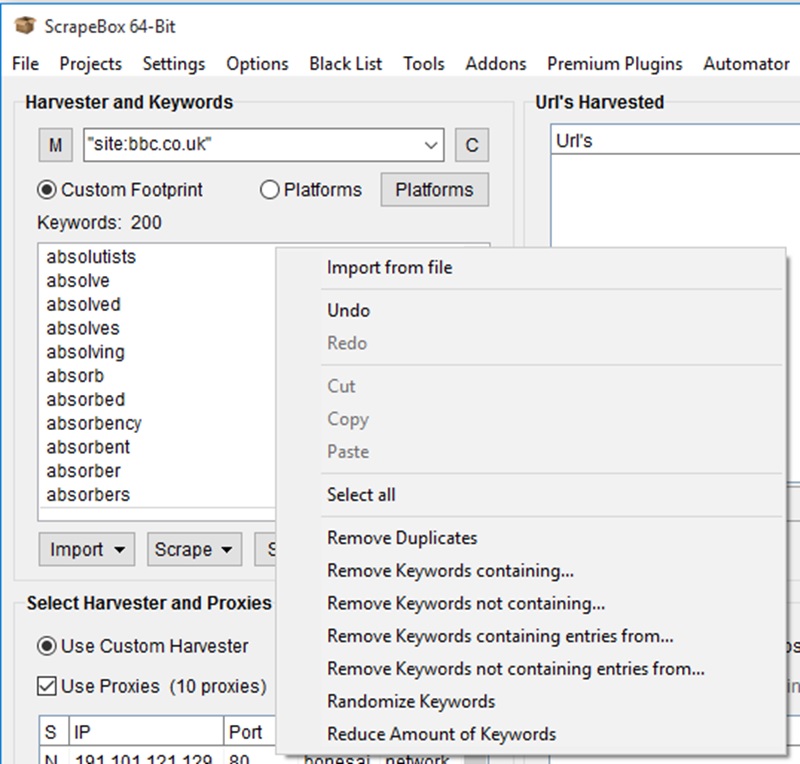
To mimic this we just add in our keywords into the field below our query/footprint. We want to use a ton of keywords
We typically only want to do around 200-1000 at a time with a low amount of proxies otherwise you might find them burning out.
Let’s go ahead and open the keywords and paste them into the keyword area.
Now our footprint and keywords are setup correctly we can jump to the next section where we are going to start harvesting some BBC webpages.

4. Harvesting URL’s & Extracting Links
We are almost ready to start the harvester up, we need to set the amount of threads/connections our harvester is going to use which is based on how many proxies we have.
we just divide proxies by 10 or 5 to come up with the right number. In this example we will divide by 5 and use 2 threads with our 10 proxies.
Simply click on ‘Settings’ in the top navigation bar and go to ‘Connections, Timeouts and Other Settings’.
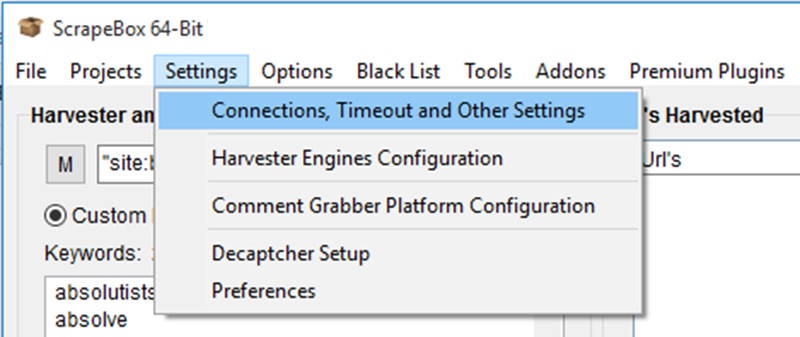
We want to change the ‘Harvester’ connections to 2. Just drag the scroller all the way to 1 and then push the right arrow key to get to 2. Press ok.
We are now ready to start it up. Make sure to go over this checklist to make sure you have it all done correctly:
– Footprint/Query: “site:bbc.co.uk”
– Keywords: 200 general keywords taken from our 10k list.
– Proxies: 10 dedicated proxies we got from buyproxies.org, also make sure the ‘use
– proxies’ checkbox is ticked.
– Connections: Harvester set to maximum of 2 connections/threads.
Now click the ‘Start Harvesting’ button.
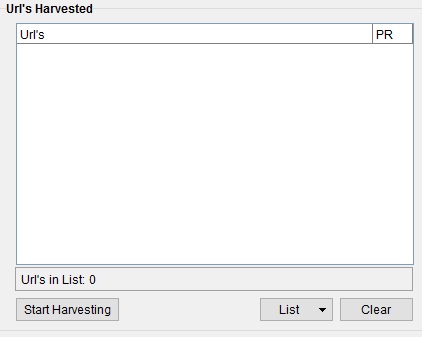
Then make sure only Google is ticked in the left hand column. It will also say proxies enabled at the top. Down the bottom it will say how many keywords you are using.
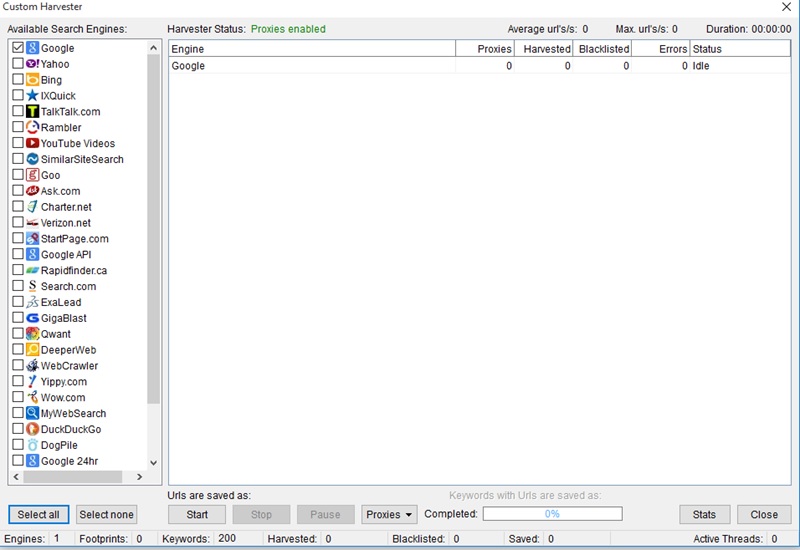
One thing to look out for while scraping is the ‘Blacklisted’ column. This shouldn’t be a problem if your using 1-2 threads per 10 proxies but if you watch it and see a proxy get blacklisted you should will pause harvesting for a while.
A blacklisted IP will become good again after a few hours. Now hit the ‘Start’ button and watch it go to work.
This may take 1-10 minutes depending on your computer & internet connection. we are using a cheap $15 VPS and that was pretty quick so your desktop or laptop should do really well too.
Once finished you can close the keyword screen that pops up and you will be able to see what happened like in the image below.
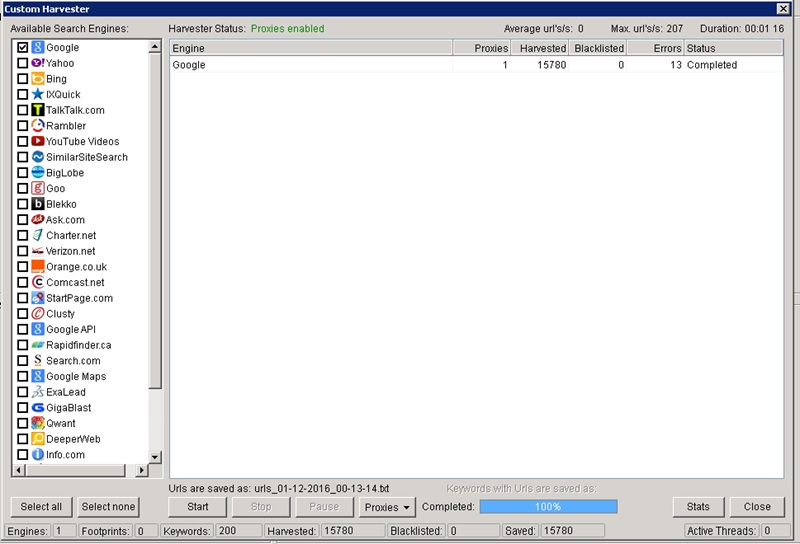
15780 URLs in just over a minute, not bad!
Now we can just click ‘Close’ in the bottom right and go back to the main harvester screen where we will filter out duplicate domains etc.
Simply go to ‘Remove/Filter’ and ‘Remove Duplicate URLs’. Now you are left with just over 13,000 URLs.
Now we need to scrape all these URL’s and find their external links where we are hoping to find some which are expired domains.
Go to ‘Addons’ at the top navigation and click ‘Show available Addons’.
Find the ‘Link Extractor’ Addon and click install in the bottom left.
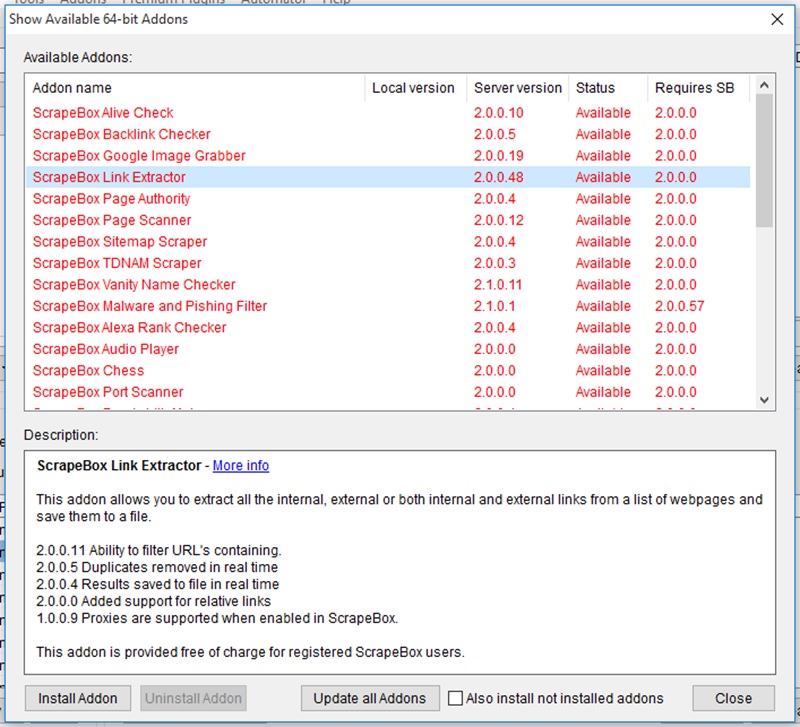
It will be highlighted green once you have installed it. You can close this now. Go back to ‘Addons’ at the top and now you can click on ‘Link Extractor’.
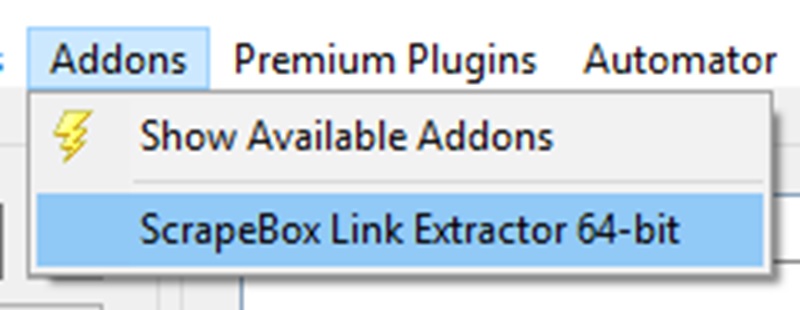
Go to Load & Load URL list from Scrapebox harvester.
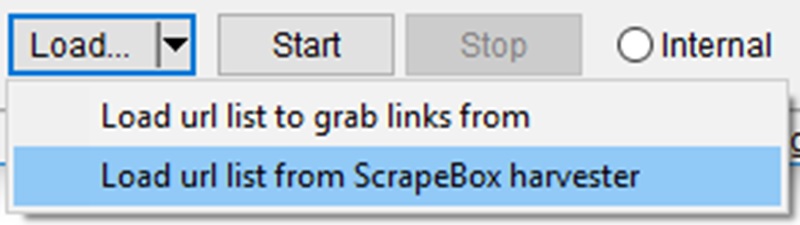
Now make sure to have ‘External’ chosen at the bottom and you will have a list of urls’s
Now we need to do a bit of setup in the settings so click on ‘Settings’ now. Make sure your settings are the same as we have below.
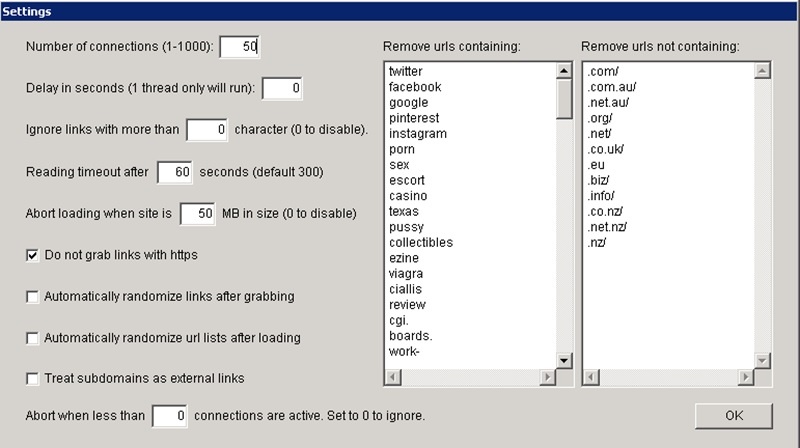
You can copy the ‘Remove Urls Containing’ & ‘Remove Urls not Containing’ by clicking on the appropriate links.
In the remove urls containing column we are basically trying to minimize spam and URLs that have no use to us which will make our job easier long term.
If you ever find a pattern of spam related to certain words in the domain url feel free to add it to the list so you can filter it out automatically.
we also make sure to select ‘Do not grab links with https’ on the left. You can play around with the number of connections however you like.
Once you have the settings all done hit ‘Ok’ and then you can start the scrape. Shouldn’t take too long until it finishes then you will have something like below.
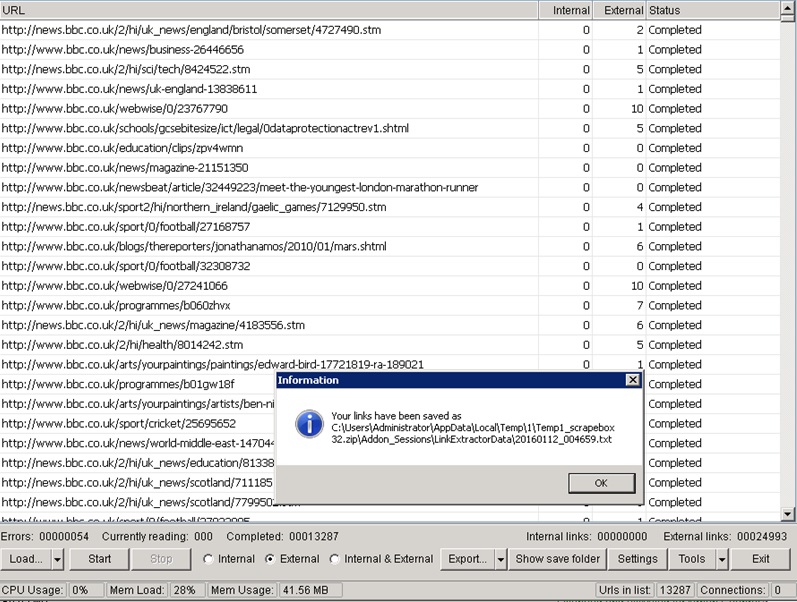
Click ‘OK’ and then hit the ‘Show Save Folder’ button

You should see your file.
Close the Link Extractor and drag this folder into the harvester where the BBC Urls are and it will clear them out and put all the external URL’s we just scraped in there instead.
Once you have completed this and your link extractor URL’s are now in the harvester section you can move on to the next part.
5. Checking For Available Domains
Now we want to clean this list up a bit so we will do the following. On the right hand side you will see a list of different things shown below.
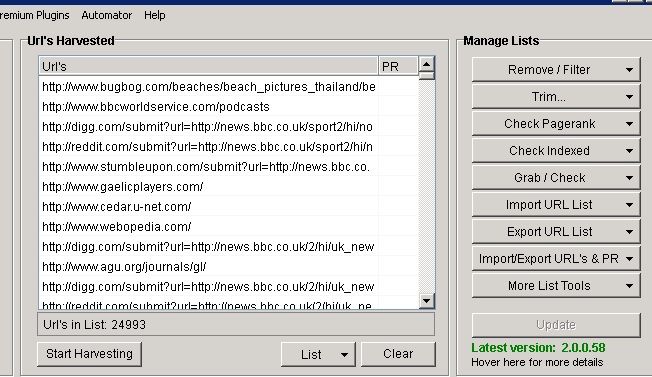
– Go to ‘Trim’ > ‘Trim To Root’.
– Now go to ‘Remove / Filter’ > ‘Remove Duplicate Domains’
– Now go to ‘Remove / Filter’ > ‘Remove Subdomain From URLs’
– Now go to ‘Remove / Filter’ > ‘Remove Duplicate Domains’ again.
– Now go to ‘Export URL List’ > ‘Export all URLs as Text’ just incase your scrapebox
crashes you have them all saved so you don’t need to re do it.
You will now have a list of unique domains that BBC has linked to. Lets try to find out if any are expired.
With our newly filtered list of domains in the harvester we are going to check to see if any are available. We will be using the Scrapebox availability checker which isn’t always 100% accurate but it does the job well enough.
Let’s start, go to ‘Grab / Check’ and ‘Check Unregistered Domains’.
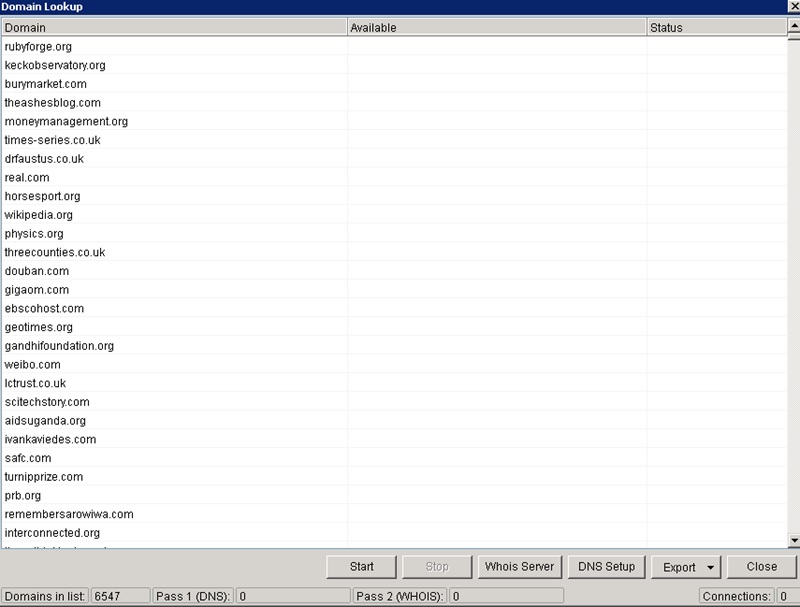
Then we just hit start and let it do its thing.
Once finished you will be able to see how many domains it checked for WHOIS data down the bottom, this is how many domains it could find that might be available which they checker again properly with the WHOIS server to verify.
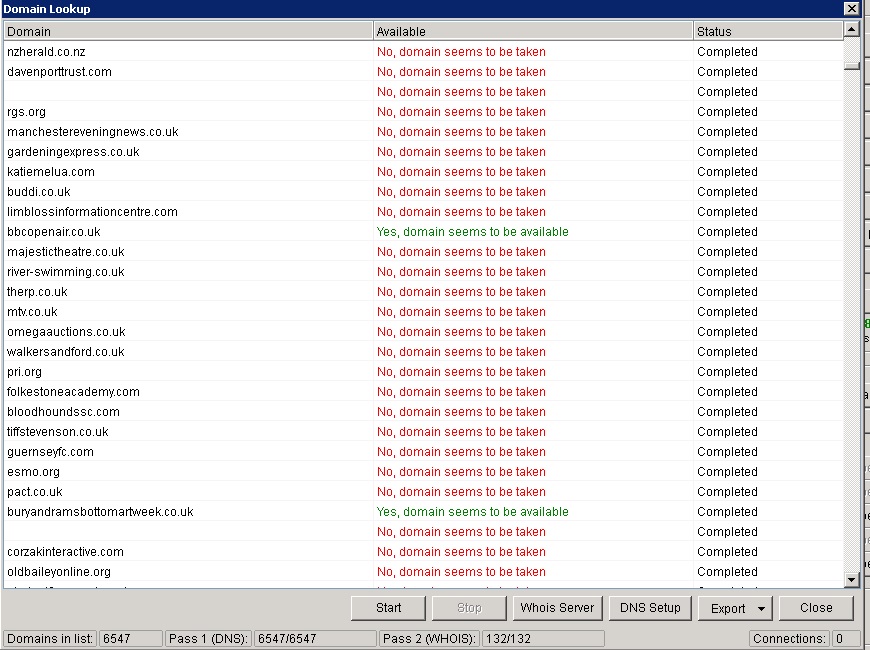
We want to export all available domains by going to ‘Export’ > ‘Export Available Domains’.
Remember where this file is and what it is called as we will need it in the next section!
6. Filtering Domains Using Majestic Metrics
First off for this section you are going to need a subscription to Majestic which will cost you around $50 dollars per month.
The website is https://majestic.com
Once you have signed up and logged in it’s time to set up our domains in an Excel/Google document so we can add to the bulk checker tool in Majestic where we will filter out domains.
For this example we are going to use Google Spreadsheets which is free and a bit easier to use than Microsoft Excel.
First copy your domains into the the document and create a new column on the left (right click add column to left) which we will fill with http://www. as shown below.
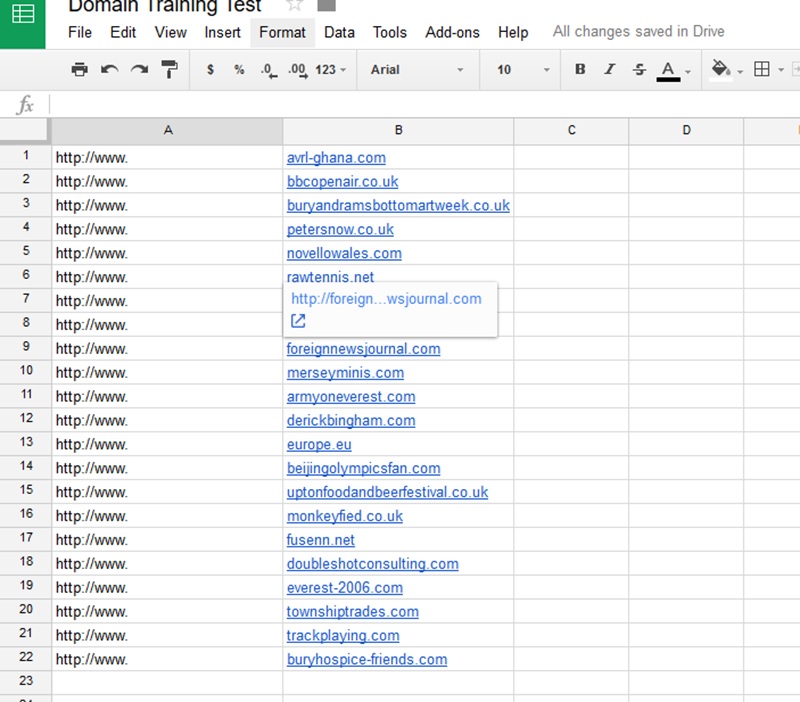
Now we want to join column A & B to create http://www.domain.com. we generally find that most domains have their links pointing to the http://www.domain.com version of the site and not http://domain.com which is why you should check with the www.
if you have the time and don’t mind messing around a little you can check both to ensure you don’t miss out on any domains.
In column C lets input =a1& b1 to join them. Then double click the little square in the bottom right of the cell to apply to all your domain rows.

Copy all the new URL’s to a text document like notepad. Save the document so we can upload to Majestic. Open up http://majestic.com and login.
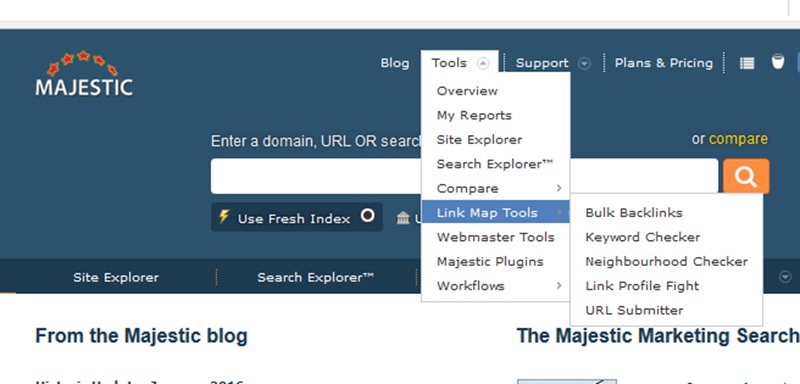
Up the top you want to go to ‘Tools’ & ‘Link Map Tools’ & ‘Bulk Backlinks’.
Once the page loads you will see two tabs, click on the ‘Upload File’ tab, leave the single column option ticked and then upload the file we just saved.
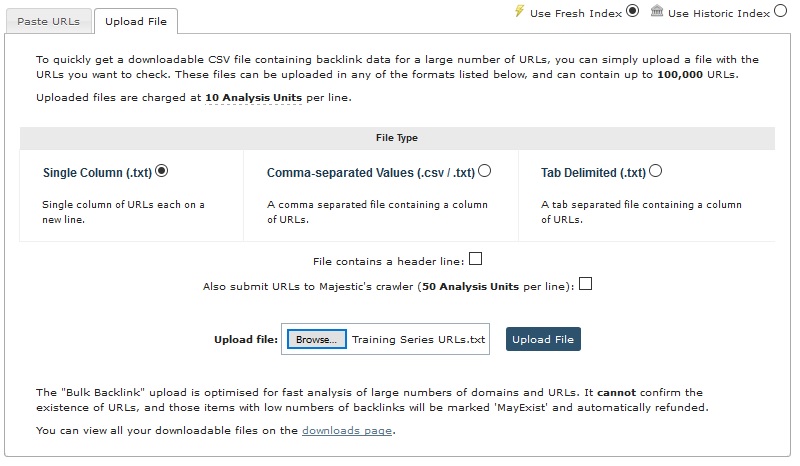
Once you hit upload it will ask you to hit accept and it will use up some of your monthly allowance.
You will then be taken to the downloads page where you will be able to download your file once it has finished being checked. Wait a minute or two and refresh the page and you will be able to click on your file to download it.
Then open it up in Google docs/Excel or whatever spreadsheet program you use.
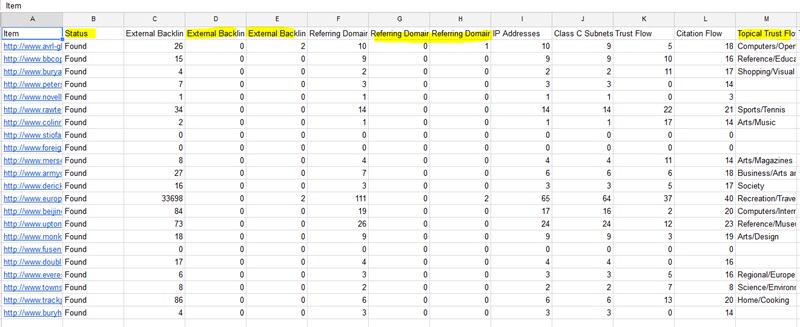
Lets setup our filter so its super easy to find domains we want to check further. Click on the ‘1’ for the first row to select the entire row.
![]()
With that row selected go to ‘Data’ at the top and click on filter which will then give all your columns a drop down arrow.

Lets filter the ‘Trust Flow’ column first. Click on the arrow for the ‘Trust Flow’ column and you will see all these numbers.
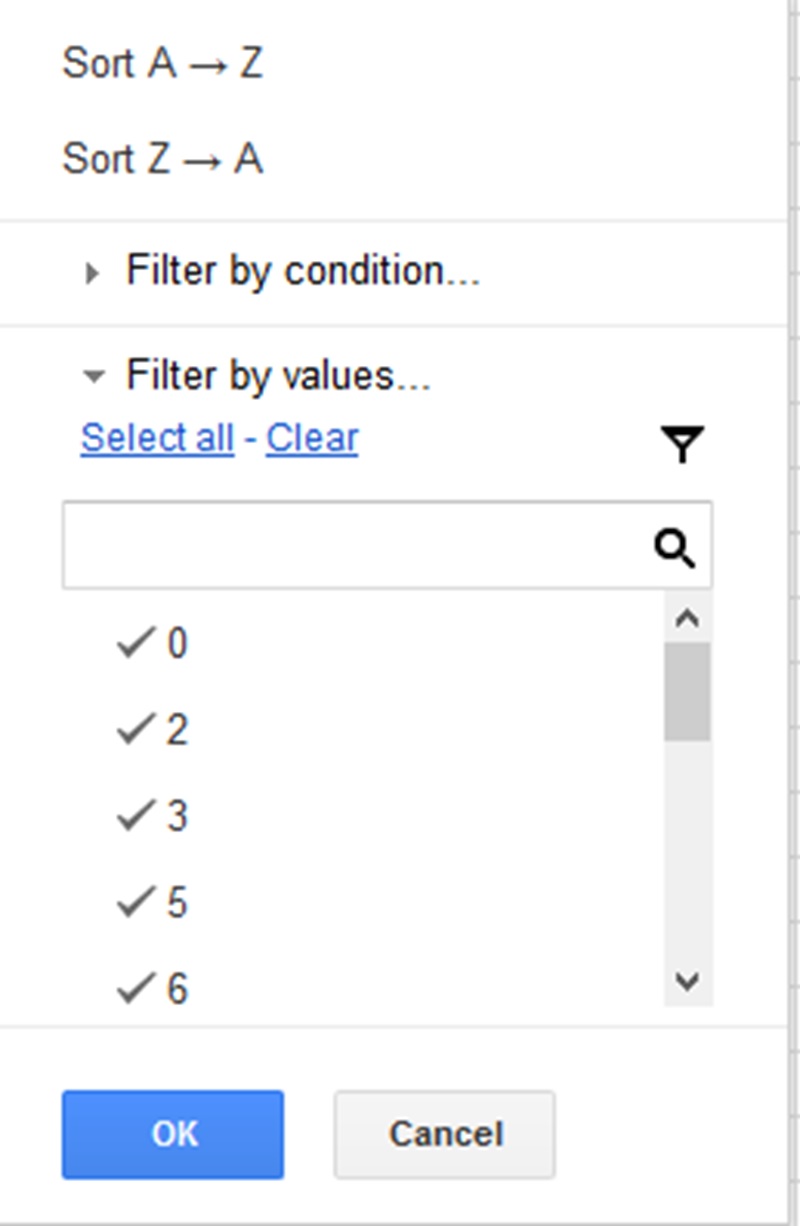
Click on anything that is between 1-14 to untick them so we will only see domains with a trust flow above 15. Now you will be left with far fewer domains.

Then we want to filter the ‘Referring Domains’ column and get rid of anything with referring domains between 1-9.

This leaves us with 2 domains to check further.
Another thing to look at is the ‘IP Address’ and ‘Class C Subnets’ columns we want the numbers in these columns to be close to the amount of ‘Referring Domains’ if there is a noticeably big gap between these it can quite often be a good idea to get rid of those domains as it can indicate that the site had a poorly setup PBN pointing to it.
Now that we have filtered our results we are going to double check that the domains are available using https://namecheap.com.
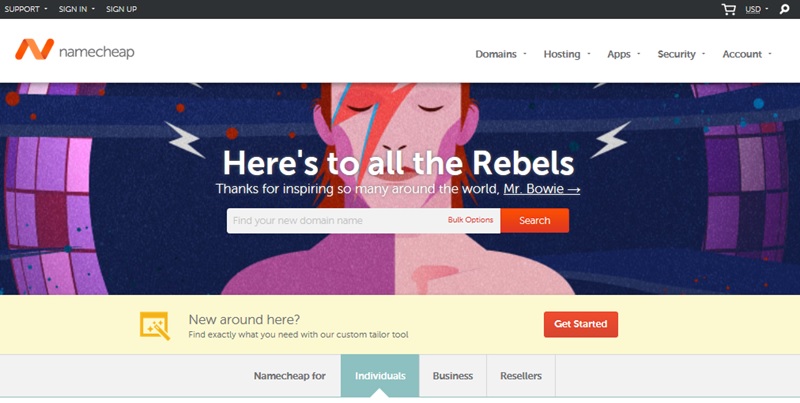
In the search field you will see the option to ‘Bulk Options’ click on that.
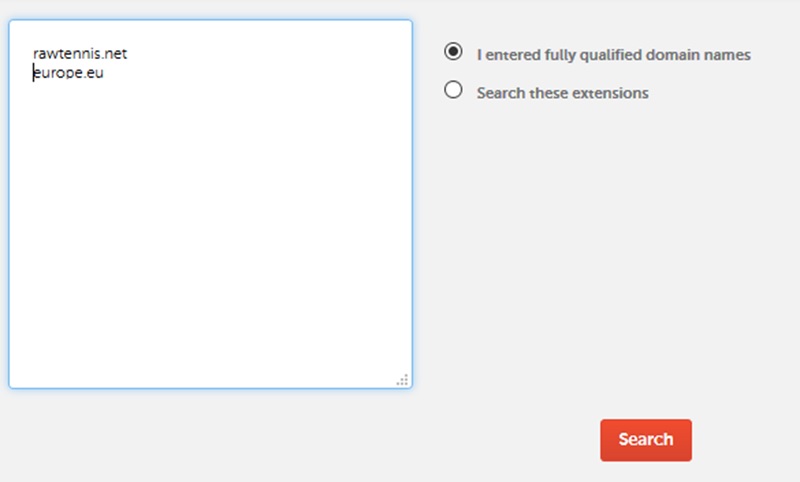
Paste your domains in, make sure to remove the http://www. and ‘/’ from them so it’s just the root domain. Make sure ‘I entered fully qualified domain names’ is checked and hit ‘Search’.

In this example only one of the domains is available. Let’s go back to our spreadsheet and remove the domains that were unavailable.
Please note that while you may notice there are slightly quicker and better ways we could be checking such a small number of domains, we are showing you exactly how to do everything based on potentially 1000’s of domains.
Now your spreadsheet will be showing available domains that fit into our metrics filtering.

It’s time to check these domains manually to make sure they are not spammy.
Jump over to http://majestic.com and enter your domain into the search bar, we want to use the root domain to check our anchor texts/links as it will show all the links that went to the site whereas if we were to check http://domain.com that would be checking the
homepage only.
Hit search.
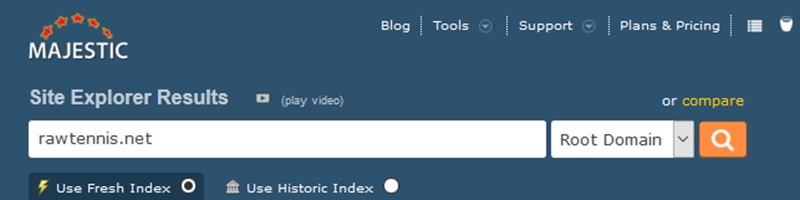
Now lets check the anchor text of this domain so you will see an ‘Anchor Text’ tab which we are going to click on.
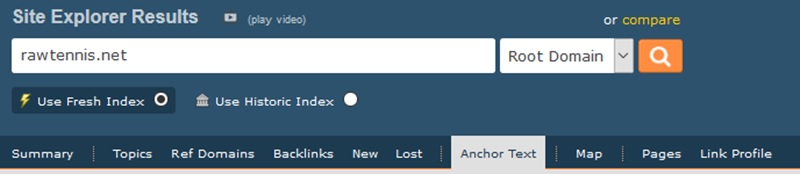
We are looking for anything that looks spammy, obviously had SEO done to it or foreign anchor texts which could indicate links from GSA and other spammy platforms.
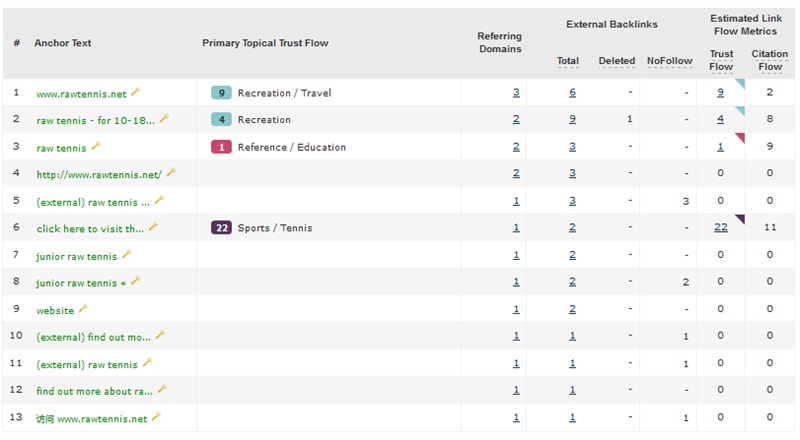
As you can see this domain has a lot of URL/Branded types of anchor texts and nothing that stands out as obvious SEO which could be something like “Best tennis shoes” “Top 10 tennis rackets” basically anything that someone would purposely try to game in the search engine.
There is however a minor chinese anchor at the bottom with the URL but in this case it seems harmless and probably just naturally occurred due to content being shared or cited.
If you look at the Referring Domains column you can see how many times a certain Anchor text is used to get an idea if something is spammy.
For example if they had an anchor text in there of “Best tennis shoes” but all the other anchor texts seemed branded/natural we want to look at the referring domains column to see how many times it has been linked to with that anchor text,
if it was only once it is probably safe to assume that the domain hasn’t been penalized or SEO’d badly.
If however there was 10 referring domains with that anchor text we will know that someone has built this site and tried to rank it and probably failed, potentially being penalized so you don’t want to pick it up.
If they have a lot of SEO looking keywords even with low referring domains you should also consider the domain bad. if the anchor texts are keywords someone would try to rank for or more natural.
So we have gathered that this domain has perfectly fine anchor text, I would mark it off in my spreadsheet with an ‘Anchor Text’ column with a ‘Y’ in it.
we also added in a ‘Wayback Machine’ column & removed the ‘IP Address’ and “C Class Subnets’ column has we don’t need them anymore as we already checked to make sure the domains were ok in those columns.
Backlinks Tab
One last thing to check in majestic is the ‘Backlinks’ tab. We want to see the Trust Flow of backlinks coming into the site and make sure it has at least 3 with over 15+ Trust Flow like below.
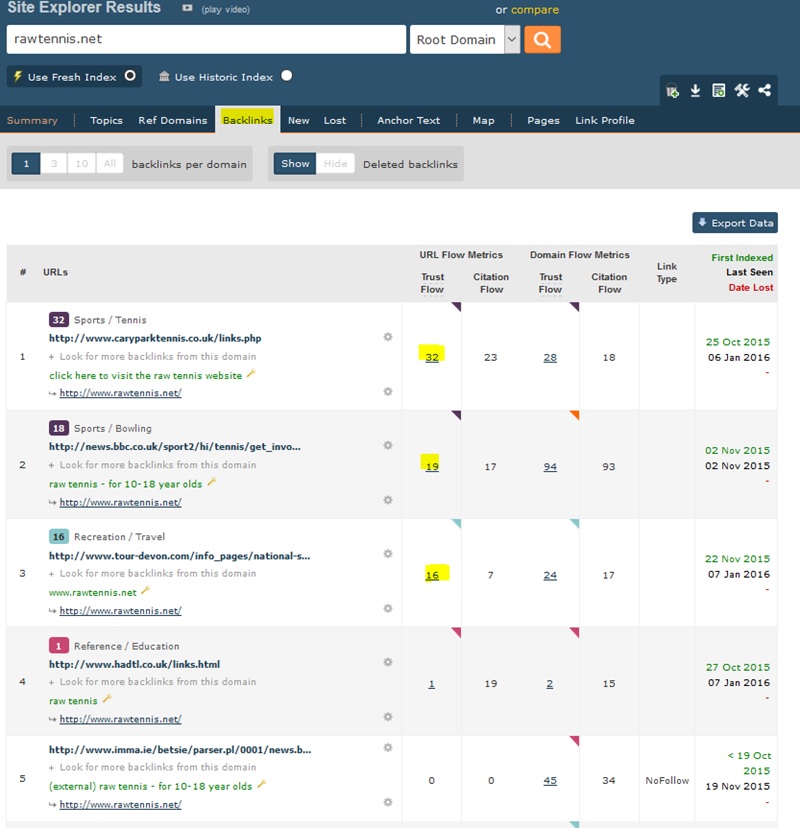
The reason you want at least 3 with good Trust Flow is because if one of those links is deleted then the domain won’t drop to 0 Trust Flow as it has more than 1 decent backlink.
Please note that we am not directly saying you should rely on Trust Flow to determine the power of a website or of a link but we definitely think that it is a good indicator that there are decent links from decent sites and at the end of the day if you sell domains this is what people are going to look at.
You can also see that the BBC.co.uk link is there and still active which is great!
7. Checking Domains In The Wayback Machine
With the Wayback Machine we are going to be checking to see what the websites used to look like and try to make sure they were not used for a Private Blog Network or foreign language spam site.
Jump over to http://archive.org.
Add the domain you want to check into the search bar at the top and push enter.
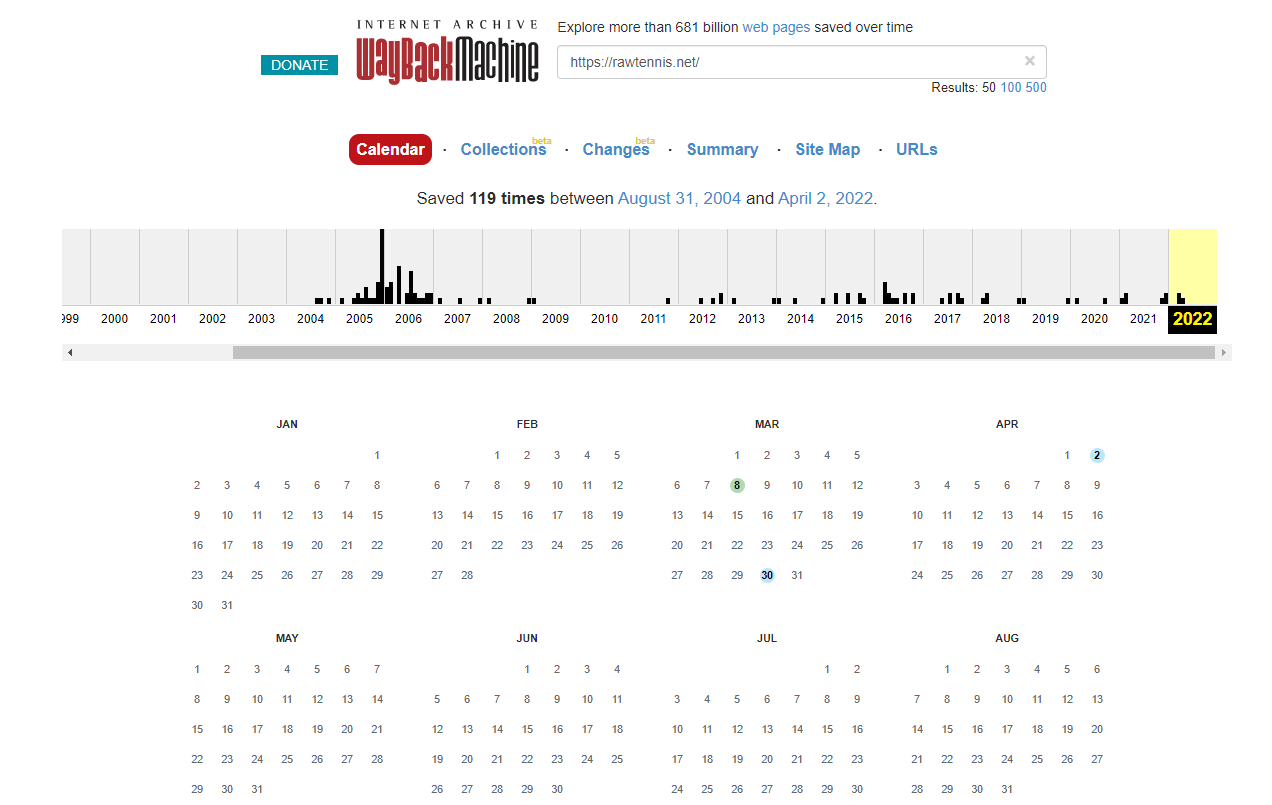
Here it will show you all the history they have archived for your website. In the above example you can see that the website seems to have been registered in 2004 then expired in 2008/2009. The website was re registered in 2012 up till 2022.
This could mean that the site is potentially been picked up and used for a PBN or Spam so what we will do is click on a black line for each year and then click a blue dot on the calendar.
And look what we have here….
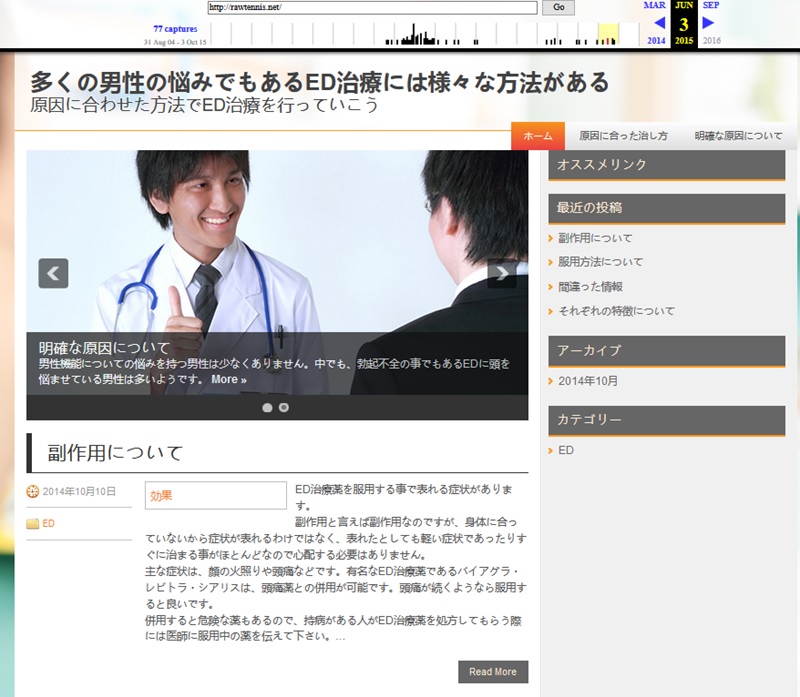
It was picked up and used as a chinese site so you should go back to my spreadsheet and put a ‘N’ in the Wayback Machine column.
You will find that a lot of expired domains have been re registered and turned into a chinese site and whilst this doesn’t mean it was used for spam or dodgy seo.
it is safer to not register these at all even though we have found most to become indexed.
we think it would be a red flag for a website to be in english, chinese and then english again and may be justification for a manual review in the future or if they want to deindex sites that have these histories in the algorithm.
You will also find that no one will buy these off you and suspect a lot of you will want to sell domains so you are better off making sure they are clean to avoid troubles.
Also if you sell a domain to someone and they check it in more depth and find what they think is spam you should definitely take a look and consider a refund if you think they are right, even if I thought they were wrong you would probably refund them as long as
they didn’t register it already.
If you check the Wayback machine and find that a page has been redirected that is fine in almost all cases as they will redirect their previous domain to their new one until it expires.
You will also find that sometimes a domain won’t have history and that’s fine too.
Checking More Pages
Since this domain was found to be bad on the first year/date we checked there is no need to check the other years but if it was good then we would just keep checking one date from each year that has a black line until we either find something bad or see that it is perfectly good.
Check more Articles:
How To Build A Web 2.0 Private Blog Network
How To Build A PBN (Private Blog Network) In 2022
How To Use Guest Blogging For Link Building Strategy
Get Powerful Links Through Competitor Link Mining
How To Sell Backlinks : Everything You Need To Know ( 100% White Hat )
Consider Following a Course ?
With Lifetime Access ?
We have been the number 1# platform for delivering most demanding course. Becoming Lifetime Member , You will receive all the Premium content For FREE
")
Consider Following a Course ? With Lifetime Access ?
We have been the number 1# platform for delivering most demanding course. Becoming Lifetime Member , You will receive all the Premium content For FREE






